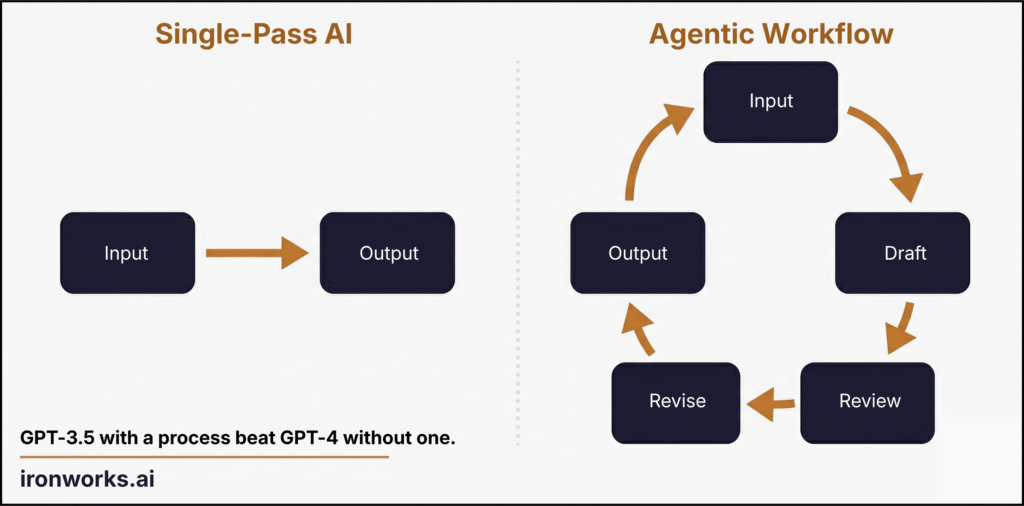
Why Process Beats Raw Capability: What Andrew Ng’s Agentic Workflows Mean for Your Operations
GPT-3.5 in an agentic loop scored 95.1% on coding benchmarks. GPT-4 zero-shot scored 67%. The cheaper model with a better process won. Here's what that...
Read more