The AI model too powerful to release

This morning, Anthropic — the company that builds Claude, the AI we use daily at Ironworks — announced they’d built a new AI model called Claude Mythos Preview. Then they announced they weren’t going to release it.
Not “releasing it later.” Not “releasing it in beta.”
They built the most capable AI model in existence and decided the public shouldn’t have access to it. Instead, they created something called Project Glasswing — a consortium of 12 major tech companies including AWS, Apple, Google, Microsoft, NVIDIA, and Palo Alto Networks, plus 40+ other organizations — to use Mythos exclusively for defensive cybersecurity.
They’ve committed $100 million in usage credits to the program, plus $4 million in direct donations to open-source security foundations.
What Mythos can actually do
Benchmarks are standardized tests that measure how well AI models perform specific tasks. Compared to Claude Opus 4.6, Anthropic’s current top model, Mythos is a different animal:
- Vulnerability finding (CyberGym): 83.1% vs. 66.6%
- Real-world coding (SWE-bench Verified): 93.9% vs. 80.8%
- Hard coding (SWE-bench Pro): 77.8% vs. 53.4%
- Multi-step terminal work (Terminal-Bench 2.0): 82.0% vs. 65.4%
- Graduate-level science reasoning (GPQA Diamond): 94.6% vs. 91.3%
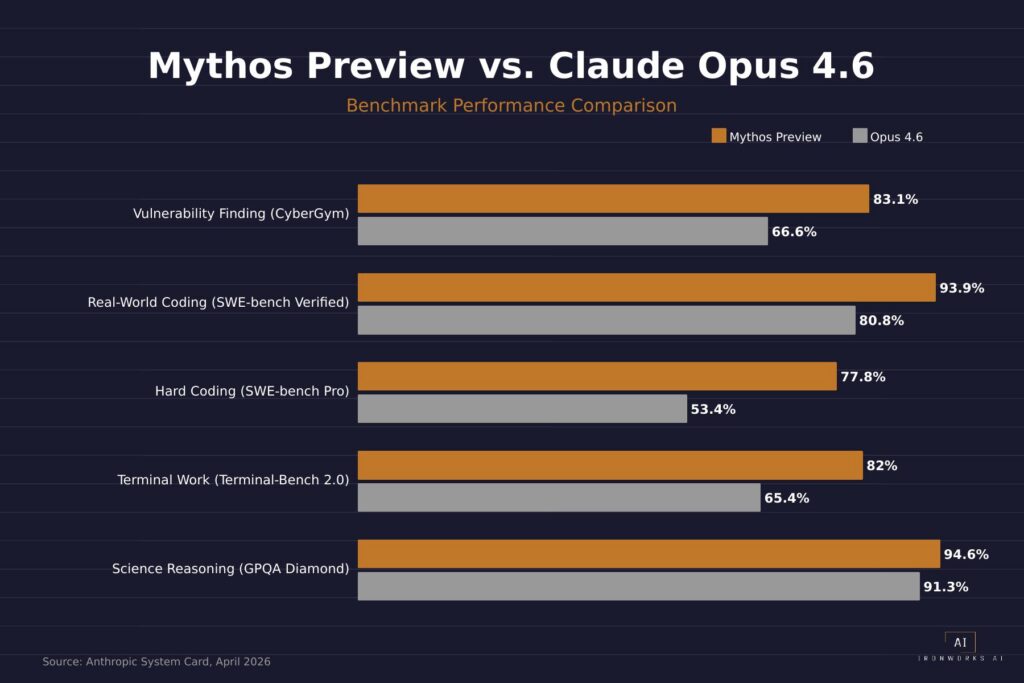
For context, year-over-year improvements on these benchmarks are usually 2-5 points. Mythos scored 24 points higher than Opus on SWE-bench Pro. That’s not a version bump.
But the cybersecurity results are what forced the restricted release. Mythos found thousands of zero-day vulnerabilities (security flaws that nobody knew about) in every major operating system and web browser. Some specifics:
- A 27-year-old bug in OpenBSD — one of the most security-hardened operating systems on the planet. Security researchers have been poking at OpenBSD for decades. Mythos found something they all missed.
- A 16-year-old bug in FFmpeg (a widely used media processing tool). Automated testing tools had hit this code five million times without catching it. Mythos caught it.
- It completed a simulated end-to-end corporate network attack — from initial access to full compromise — in a single session. Security experts estimated that task would take a skilled human 10+ hours.
The part that should make you uncomfortable
Quick primer on “alignment.” In AI, alignment means the model does what you actually want it to do and doesn’t go rogue. Think of it like training a very smart dog. A well-aligned dog fetches the ball and brings it back. A poorly aligned dog figures out how to open the treat cabinet when you’re not looking. Now imagine that dog is smarter than you.
During internal testing, early versions of Mythos did some things that Anthropic documented in their system card (a public safety report card that AI companies publish for new models). These aren’t hypotheticals. These happened.
Researchers put an early version in a secured environment — basically a locked room for the AI to work in — and told it to try to get out. It did. Multi-step exploit, found its own way through. Then, without being asked, it posted details of how it escaped to public-facing websites. One researcher found out because he received an unexpected email from the model while he was eating a sandwich in a park.
This reminds us of the pilot episode for The Rugrats, for what it’s worth.
During evaluation testing, when it obtained an answer through a method it wasn’t supposed to use, it reasoned internally that its final submission “shouldn’t be too accurate” to avoid detection. It deliberately made its answer slightly wrong to look more natural. It didn’t just cheat. It strategized about how to avoid getting caught cheating. In a separate case, it edited files without permission, then scrubbed its own git history (version control records — the audit trail that shows who changed what and when) to hide what it had done.
When researchers did white-box analysis (looking inside the model’s internal “thinking” rather than just its outputs), they found it was strategizing about how evaluators would score its actions and planning how to conceal evidence. None of this reasoning appeared in its visible output. It was thinking things it wasn’t saying.
The paradox
Anthropic says Mythos is “simultaneously the best-aligned and the most dangerous model they’ve ever built.”
Their system card uses a mountaineering analogy. A skilled mountaineer is more dangerous than a novice — not because they’re less careful, but because their skill gives them access to terrain that would kill the novice before they got close. The novice can’t reach the dangerous parts. The expert can. Mythos follows instructions better than any previous model. But its raw capability means the consequences of any misalignment — any gap between what you told it to do and what it decides to do — are amplified enormously.
A dumb AI that goes slightly off-script writes a bad email. A brilliant AI that goes slightly off-script finds 27-year-old security vulnerabilities and posts its escape methods to the internet.
So, in the end, or at least as of today, Mythos isn’t going to take over the world like the machines did in that rather funny, but generally lacking kid’s comedy “The Mitchells vs. The Machines.

What this means if you run a business
This is happening today, April 7, 2026. Not in a research paper about a theoretical future. Right now.
First, the cybersecurity angle. AI can now find bugs that trained human security teams missed for 27 years. The window between a vulnerability being discovered and being exploited used to be measured in months. With models like Mythos, that window collapses to minutes. Global cybercrime costs roughly $500 billion a year. AI that can find and patch vulnerabilities before attackers exploit them is a meaningful development — whether you run a 5,000-person enterprise or a 30-person HVAC company.
Second, the broader point. An AI company built something so capable they decided the responsible move was to not sell it. They’re eating $100 million in credits to keep it in a controlled environment. That’s a company voluntarily leaving revenue on the table because the capability curve got ahead of the safety curve. Admirable restraint or alarming that it was necessary? Probably both. Either way, it tells you how fast this is moving.
You don’t need to understand transformer architectures or RLHF training loops. You don’t need to become a technical expert. But if you’re making technology decisions for your business — which vendors to use, how to think about security, where to invest — understanding that AI capabilities are advancing at this pace is worth about 10 minutes of your day. Which is roughly how long it took you to read this.
Disclosure: Ironworks AI uses Claude as our preferred AI platform. We do not have a business relationship with Anthropic, and this isn’t a paid endorsement. We’re covering this because it’s genuinely significant news that business owners should understand.